
I'm viewing it through the lens of computation, though not necessarily in machine terms; from the perspective of memory and instructions, there's certainly a clear difference between M*N and 2M*2N arrays regardless of what they contain, since you can't plug one into a function designed to address the other and receive the same (or indeed, sane) output.Bassa-Bassa wrote: ↑Thu May 23, 2024 10:31 am Night and day, but you must not think about this in computing terms.
To be honest, I was afraid of not being understood by everybody, so likely it's my fault there as what I'm saying goes against any modern (and not so modern) mindset, and I knew it. When you digitally scale x2 a picture even without any resampling process you're indeed making a change in detail - you're using the computer to fill in the gaps between pixels with clones of them, so you're preventing you mind of picturing (imagining) properly any given detail a group of pixels are representing. In other words, the gaps were part of the detail itself (even if you usually don't perceive them as gaps, or actually, because of that) and filling them with /whatever/ is adulterating the intended picture.
Doubling or multiplying pixels is in actuality an artifact like any other - it's just the easiest one a computer can do. Of course, it's also a necessary thing as we're on a digital medium and well, it just seems to be the less arbitrary. It's still arbitrary, nonetheless. Leaving the gaps empty would be a more natural thing to do when upscaling digitally, but then again it wouldn't work in non-granular processes and it'd de-naturalize other aspects, so few people paid any attention to it. Until shaders, I want to believe. With all the issues they're still facing I'm hoping they become common use for your everyday digital upscaling when our screens get better, and not just for videogames.
If we define detail as being equivalent to memory layout, i.e. how many pixels total can fit in an image, then it's correct to say that any change to that structure or the data within - even if trivial - is quantifiably different, and can be proven so by running a byte-for-byte equality check.
However, quantitative equality isn't sufficient to cover the complexity of computer vision - looking back, I probably should have said "qualifiably different" re. equivalence of multiply-scaled images, since the quantities are the RGB values within the raster array, but I'm getting at a more abstract notion.
For a worked example, consider the relatively common quadtree optimization that comes up in compression and rendering. Assuming a square image for simplicity:
1. Overlay a 1x1 grid cell on top of the image
2. If all pixels within the cell are the same color, set that as the cell's color and return.
3. If they're not all the same color, sudivide the cell into a 2x2 sub-grid, and start over from step #2 in each cell.
Since - worst-case - a repeatedly-subdivided cell will eventually become as small as one image pixel, this terminates with an adaptive-resolution grid that combines identically-colored square regions.
Something like this:
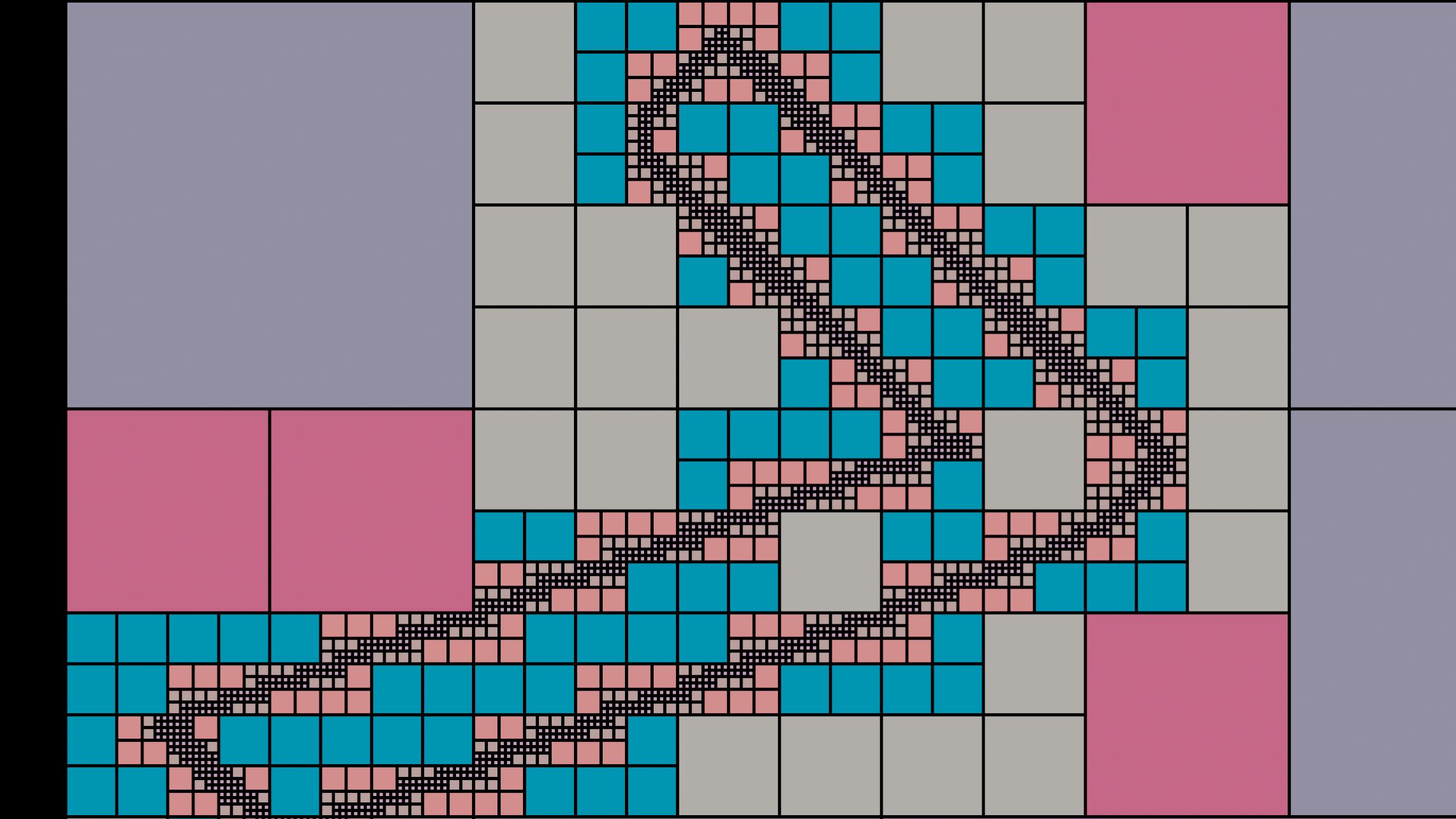
And if you were to apply it to the case of 2x (3x, 4x .. Nx) scaling, this routine would end up encoding the same set of pixels as the original 1x raster. Thus on some level, the act of whole-factor scaling must be an identity operation - a notion supported by the reversible / inverse property inherited from multiplication and division.
(You could also take the idea further, and merge identically-colored adjacent cells into 1xN / Nx1 regions to get an even sparser encoding than the original source image!)
Those qualitative properties are how I define detail for images, since - as shown - they can be encoded in different ways and still mean the same thing. If we divorce the issue from displays entirely and look at a more physical analogy - say, implementing the rasterization or block-fill routines manually IRL by laying out a mosaic of appropriately-dimensioned tiles - it becomes apparent that the raster approach creates more seams, and thus more structural artifacting; a direct analogy to the mentioned physical pixel separation.
Edge-cases like the 3DS' large low-res panel obviate the issue, but standardized devices and viewing conditions (i.e. TVs, monitors) are generally designed to make the difference imperceptible. In that case, the brain can reify the various representations into equivalence while also dealing with rotation, perspective, stabilizing micromovements, and so on. It evidently operates on a still-more-abstract system that subsumes all of the above, so I posit that a higher-order notion of equality is needed to reason about the problem once the data leaves the memory / screen domain and makes transit to it by way of the physical.
In the strictest sense, I'd argue analog rendering is denatured by default, since it's mapping a fixed raster onto a physical medium whose structure may not align precisely with that of the source image.Bassa-Bassa wrote: ↑Sun May 26, 2024 7:36 pm Not really. It would have "got bigger" if you enlarge the picture analogically. Like when you use the monitor's control panel on a VGA PC CRT to enlarge (or reduce) the picture size. What you're doing is digital upscaling, which implies adding information, even if it's repeated information. Therefore, any detail is getting denatured, as it was defined by a determined number of pixels and their related positions.
It just happens to exploit some nice properties as an image medium, masks fine-grained enough to not destructively alias, content that's specifically authored to look good when processed as such, and lots of tweakable knobs, to create an end effect that - while 'fuzzy' by virtue of being analog - is a lot more pleasing at baseline than the digital equivalent.















{kind=link}